The Corpus InterLangue project: storing language learner data in a Huma-Num Nakala database for automatic online retrieval

The Corpus InterLangue project: storing language learner data in a Huma-Num Nakala1 database for automatic online retrieval
Project definition
The Corpus InterLangue (CIL) project is a collection of spoken and written productions from learners of English and French as second languages (L2). The corpus provides various sources of learner input completing different tasks (Ellis 2003). Learner data have been a source for evidence-based research in Second Language Acquisition for over two decades (Granger, Gilquin, and Meunier 2015). This type of data gives insights into learners’ language features which can be analysed in the light of the interlanguage (IL) hypothesis (Selinker 1972).
The CIL data have been collected since 2008 as part of a research programme conducted by the LIDILE2 research team. The data sources have been stored digitally in non-public spaces. The LIDILE team now wishes to make this data available to the community.
Corpus description
The CIL is divided into two parts which compile data of two learner profiles: learners of L2 French (CIL-FLE) whose L1 is English, Spanish, Mandarin, or Arabic, and learners of L2 English (CIL-ALE) whose L1 is French. The same data collection protocol is followed for both languages and learners perform the same tasks:
- a 10-to-15-minute semi-structured interview,
- a reading aloud task, which prompts
- a writing task.
Spoken data are transcribed and time-aligned. Handwritten text data are retyped into digital format. All transcriptions are saved in CHILDES and TEI XML compliant formats. Learner metadata have also been collected and compiled in a table-like format in .tsv files. Each column corresponds to a sociolinguistic variable. All publicly accessible data will be anonymised.
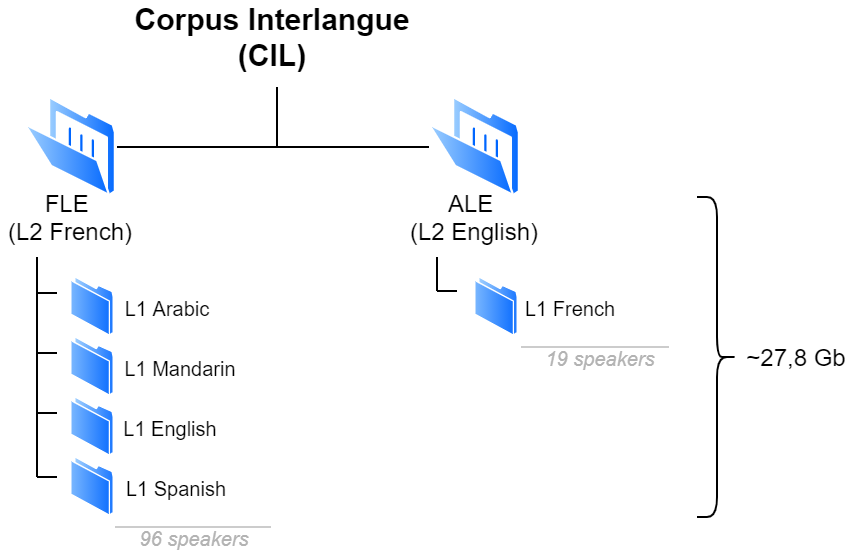 Figure 1: Structure of the corpus
Figure 1: Structure of the corpus
Database structure
The database will store three types of documents including WAV, UTF-8 text or tsv files and PDF images of handwritten documents. Each document will be characterised with Dublin Core metadata including title, author, date, file format and document type (audio, text or image). The database will be a Triplestore in the sense that all document metadata, their relationships (isPartOf…) and their collection(s) will be stored according to the RDF standard3. A REST API with SPARQL-based queries will be developed to allow up-to-date automatic retrieval of selected data by external applications. Results will be returned as JSON files.
Data workflow
The data storing workflow (See Figure 1) includes three main stages. In stage 1, users (linguists) collect the data in format compliant files. In stage 2, DC metadata files are created for each document, uploaded in batch mode and stored in RDF. In stage 3, public access will be provided to allow automatic retrieval.
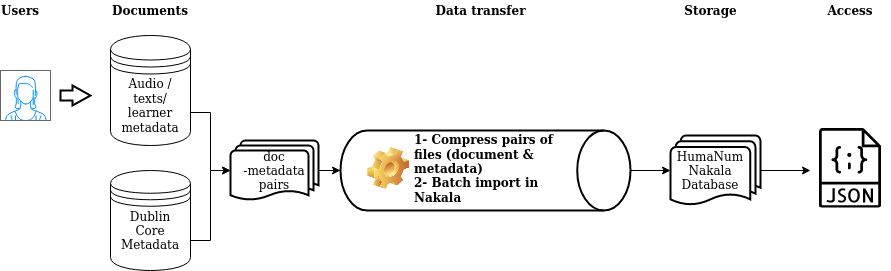
Figure 2: The “Corpus InterLangue” project: storing language learner data in a Huma-Num Nakala database for automatic online retrieval
Such work can benefit research in three main areas. AI-based Tutoring Systems may avail of up-to-date data for model training tasks. Researchers in SLA may access the data for modeling learner language according to socio-linguistic variables such as learners’ L1 and L2 exposure. Language instructors and course designers may use the retrieved data for Data Driven Learning activities.
References
- Ellis, Rod. 2003. Task-Based Language Learning and Teaching. Oxford University Press. Oxford.
- Selinker, Larry. 1972. “Interlanguage.” International Review of Applied Linguistics in Language Teaching 10(3):209.
- Granger, Sylviane, Gaëtanelle Gilquin, and Fanny Meunier, eds. 2015. The Cambridge Handbook of Learner Corpus Research. Cambridge: Cambridge University Press.
Contact: Thomas Gaillat
See https://documentation.huma-num.fr/content/14/139/en/what-is-nakala-for.html for more information on this French national project ↩︎
Linguistique et Didactique des Langues (Linguistics and Language Didactics). See https://lidile.hypotheses.org/ ↩︎
Leonardo Contreras Roa
Maître de conférences en phonologie anglaise
Phonéticien et enseignant d’anglais, Docteur en linguistique