Protocole de traitement de données en orthophonie
Étape 1 : annotation automatique forcée
[WebMAUS]
1.1 Préparation des fichiers son
Notre point de départ est un corpus d’enregistrements. Ce corpus est une collection de fichiers .wav (ou autre format son) – des enregistrements. Chaque enregistrement contient une seule phrase produite par un seul locuteur.
| Locuteur_1 | Locuteur_2 | Locuteur_3 | … |
|---|---|---|---|
| Locuteur 1, phrase 1 | Locuteur 2, phrase 1 | Locuteur 3, phrase 1 | etc. |
| Locuteur 1, phrase 2 | Locuteur 2, phrase 2 | Locuteur 3, phrase 2 | |
| Locuteur 1, phrase 3 | Locuteur 2, phrase 3 | Locuteur 3, phrase 3 | |
| etc. |
Chaque fichier audio devrait être nommé avec des conventions qui affichent au moins des informations sur :
- Le locuteur (de façon codée, pour anonymisation)
- Le groupe auquel appartient le locuteur (contrôle, expérimental, pré-test, post-test, etc.)
- Le numéro de phrase
Ces informations devraient être séparées par un caractère spécifique (par exemple, «_») et idéalement contenir que des minuscules et des chiffres. Par exemple :
gr01_loc01_phr01.wav
Ce codage permettra d’extraire ces informations automatiquement à partir du nom de fichier, ce qui permettra d’organiser plus facilement l’extraction de données acoustiques plus tard.
1.2 Création des fichiers .txt
Une fois prêts, les fichiers .wav doivent être appairés individuellement avec des fichiers .txt contenant la transcription orthographique du contenu de l’enregistrement. Ces fichiers .txt doivent porter le même nom du fichier .wav auquel ils correspondent (ils diffèrent uniquement dans leur extension).
Avec PowerShell, il est possible de créer automatiquement des fichiers .txt vides portant le même nom des fichiers .wav contenus dans un dossier. Pour ce faire, ouvrez PowerShell et placez-vous sur le chemin d’accès où se trouvent les fichiers wav :
cd C:\Directoire\des\enregistrements
Ensuite, lancez le code suivant :
foreach($File in Get-ChildItem *.wav){
$Name=$File.BaseName+'.txt'
if(!(Test-Path $Name -PathType Leaf)){
New-Item $Name -Value $File.Name
} else {
"File {0} already exists" -f $Name
}
}
Vous pouvez ensuite ajouter les transcriptions orthographiques à l’intérieur de chacun de ces fichiers texte manuellement.
Technique alternative (bêta)
Comme tous les enregistrements suivent le même protocole d’enregistrement, le contenu orthographique des énoncés produits par tous les locuteurs devrait être le même. De ce fait, nous devrions être capables d’extraire les noms des fichiers et les phrases à partir du fichier log de chaque enregistrement. Ce script R permet de transformer les phrases de tous les fichiers log en format .csv contenus dans un dossier soient transformés en fichiers .txt
library(readr)
# get a list of all the CSV files in the folder
csv_files <- list.files(pattern = ".csv")
# read in the CSV files and concatenate them into a single dataframe
all_data <- lapply(csv_files, read.csv)
all_data <- do.call(rbind, all_data)
# extract two columns from the concatenated data and save as a new CSV file
file_list <- all_data[, c("type", "repetition")]
write.csv(file_list, "fileList.csv", fileEncoding = "UTF-8", row.names = FALSE)
# Transforming the created .csv into .txt containing the sentences.
# Load the table into a dataframe
table <- read.csv("fileList.csv", na.strings = c("", "NA", "N/A"), stringsAsFactors = FALSE)
table[is.na(table)] <- "blank"
# Iterate over each row in the dataframe
for (i in 1:nrow(table)){
file_name <- table[i, "repetition"]
text <- table[i, "type"]
file.create(paste0(file_name, ".txt"))
write(text, paste0(file_name, ".txt"))
}
# get a list of all the files in the folder
file_list <- list.files()
# rename all files ending in ".wav.txt" to ".txt"
for (file_name in file_list) {
if (endsWith(file_name, ".wav.txt")) {
new_file_name <- gsub(".wav.txt", ".txt", file_name)
file.rename(file_name, new_file_name)
}
}
D’autres techniques sont possibles pour modifier les noms des fichiers en batch, si jamais ce script ne fonctionne pas 1 .
Cependant, il est possible (et très probable) que les locuteurs fassent des faux départs, des répétitions ou des erreurs de lecture. Chaque transcription orthographique .txt doit par conséquent être vérifiée afin de représenter ces variations individuelles éventuelles.
L’outil que nous allons utiliser pour effectuer l’alignement automatique, WebMAUS, a un système intuitif de correspondances graphémo-phonologiques, c’est-à-dire, il est capable de déduire la prononciation d’un mot qui n’existe pas à partir de sa graphie. Ainsi, vous pouvez assigner vos propres approximations orthographiques aux faux départs faits par les locuteurs – WebMAUS devrait être capable de les interpréter. Voici quelques exemples d’approximations orthographiques possibles :
| Énoncé produit | Approximation orthographique |
|---|---|
| [il ɛ vø il ɛ vəny] | il est veuh il est venu il est veu il est venu |
| [setɛ̃ setɛ̃posibl] | C’est in c’est impossible C’est ain c’est impossible |
| NB : WebMAUS ne prend pas en compte la ponctuation. |
D’autres phénomènes tels que des rires, de la toux, des silences ou du bruit non-vocal peuvent être annotés avec des étiquettes spécifiques afin de donner à WebMAUS des repères acoustiques pour son interprétation :
<nib>: bruit<usb>: bruit humain (toux, rires, etc.)<p:>: silence
1.3 WebMAUS Basic
Une fois les fichiers .txt et .wav prêts, il faut les mettre en ligne sur
l’interface WebMAUS. Sur le site, nous utiliserons deux des services proposés par WebMAUS : WebMAUS Basic et Pho2Syll (surlignés en jaune sur l’image2) :
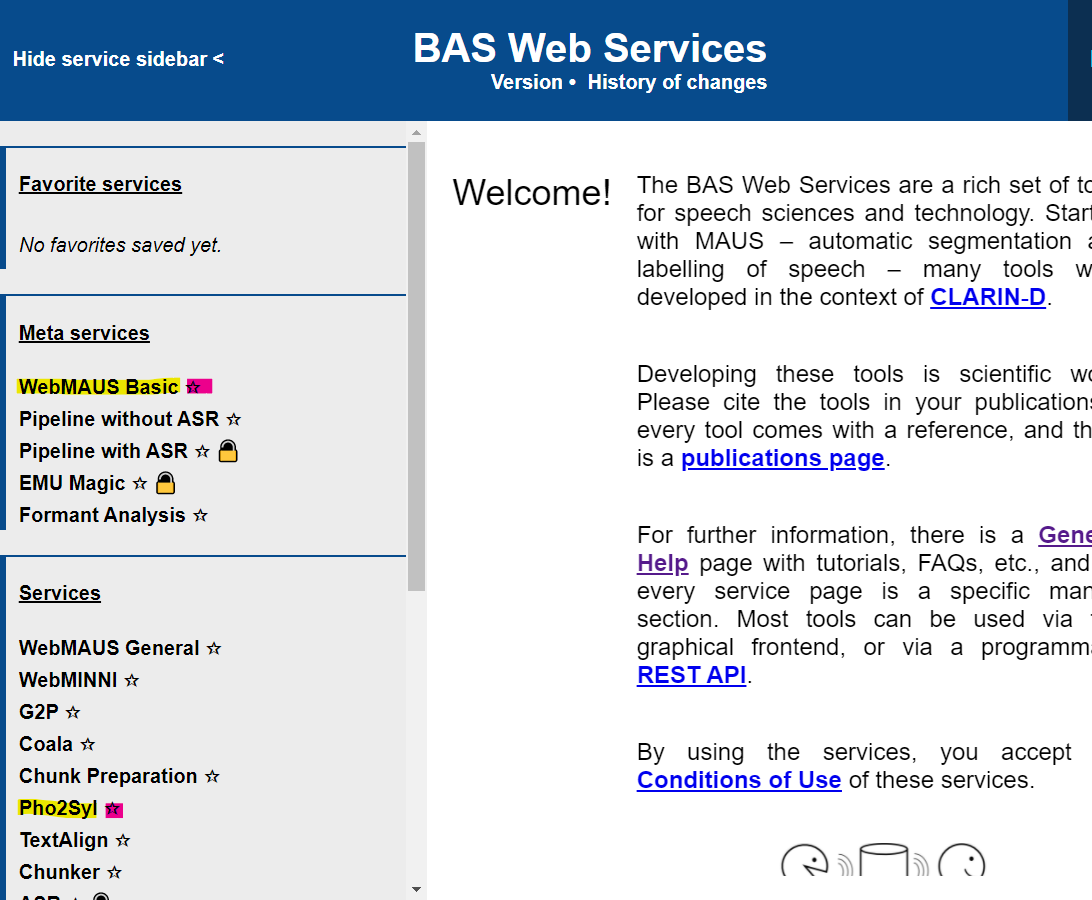
Le premier service à utiliser est WebMAUS Basic, qui réalise la transcription phonétique et son alignement forcé sur le signal sonore.
Sur la console du site web, versez les paires de fichiers .wav et .txt en cliquant et déplaçant. Si les noms des .wav et des .txt correspondent, ils seront affichés avec le symbole <=> ; si ce n’est pas le cas, c’est qu’il y a des discordances entre les noms des fichiers qui doivent être corrigées. Vous pouvez verser autant de paires de fichiers simultanément que vous voulez.
Uploadez les fichiers sélectionnés en cliquant sur  Une barre de progression apparaîtra. Ensuite, sélectionnez les options suivantes sur la configuration (Service options).
Une barre de progression apparaîtra. Ensuite, sélectionnez les options suivantes sur la configuration (Service options).
Language : French (FR)
Output format : BAS Partitur Format (bpf)
Cochez la case I have read and accepted the terms of usage, puis cliquez sur 
Un fichier compressé .zip contenant des fichiers .bpf3 vous sera proposé pour le téléchargement. Téléchargez-le et extrayez-le sur le dossier où vous stockez vos .wav et .txt.
1.4 Pho2Syl
Le processus à suivre dans Pho2Syl est similaire à celui que nous venons de réaliser, mais cette fois-ci vous devez verser uniquement le fichier .bpf obtenu à la sortie de l’étape précédente. Cette étape correspond à la syllabification de l’alignement précédemment effectué.
Ici encore, sur Service options, insérez les configurations suivantes :
Language: French (FR)
Tier name: MAU
Word synchronous: yes
Sample rate: 0
Output format: Praat (TextGrid)
Output Symbol Inventory: X-SAMPA (ASCII)
Cochez la case I have read and accepted the terms of usage, puis cliquez sur
Un fichier compressé .zip contenant les fichiers .TextGrid vous sera proposé pour le téléchargement. Vous avez maintenant des TextGrids créés automatiquement qui doivent être vérifiés et corrigés.
Étape 2 : Correction manuelle
[Praat]
La longueur de l’étape de correction va dépendre de la compatibilité de vos enregistrements avec l’algorithme de transcription automatique de WebMAUS Basic. La performance de l’algorithme peut dépendre de la qualité du son mais aussi de la prononciation des locuteurs : en effet, l’algorithme est entraîné sur des valeurs acoustiques type pour des locuteurs natifs du français et sans pathologies. Il est donc probable que vous ayez un bon nombre de modifications à réaliser.
2.1 Comment être efficace pendant les corrections
2.1.1 Déplacer les frontières des tiers
Le résultat de l’alignement et de la syllabification est un TextGrid contenant 4 tiers :
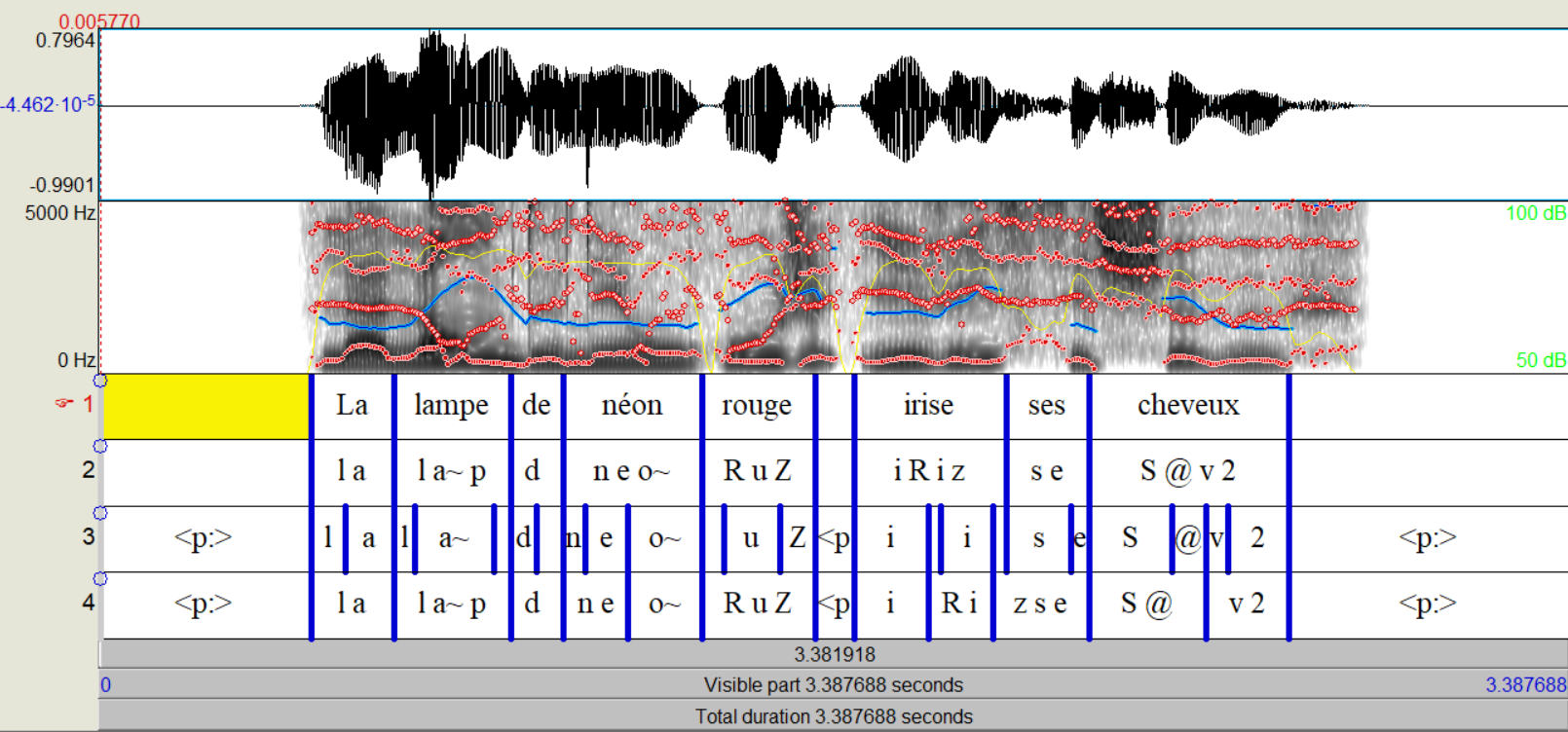
Les frontières gauche et droite de chaque annotation sont liées ou « attachées » entre elles au travers des tiers. Cela veut dire que vous pouvez les déplacer conjointement en appuyant sur Shift + clic.
Attention : si vous déplacez la frontière sur un seul tier, sans appuyer sur Shift, vous briserez le lien entre les tires et vous ne pourrez plus les déplacer en bloc.

Si vous vous trompez, vous pouvez toujours annuler votre dernière action avec Ctrl+Z (ou Edit > Undo), mais vous ne pouvez le faire que sur votre dernière action (au moins sur Windows).
Il est également possible de réattacher des frontières brisées en calant soigneusement une frontière sur la seconde exacte sur laquelle se positionnent les autres. Souvent, cela demande de plusieurs essais. Privilégiez Ctrl + Z.
Pour savoir si des frontières sont attachées entre elles, sélectionnez-en une. Toutes les autres qui sont attachées avec elle seront marquées avec un trait jaune fin au milieu du trait bleu plus épais des frontières, comme illustré sur l’image à gauche.
Une fois vos modifications effectuées, n’oubliez pas de sauvegarder les changements en cliquant sur File > Save TextGrid as text file… ou en tapant Ctrl+S.
2.1.2 Raccourcis clavier
Les boutons de navigation en bas à gauche de la fenêtre d’affichage permettent de zoomer sur toute la durée du fichier (all), de se rapprocher (in), de s’éloigner (out), de zoomer sur une sélection (sel) ou de revenir à un stade de zoom précédent (bak).

| Bouton | Raccourci clavier |
|---|---|
all | Ctrl + A |
in | Ctrl + I |
out | Ctrl + O |
sel | Ctrl + N |
D’autres raccourcis utiles sont :
| Manipulation | Raccourci clavier |
|---|---|
| Déplacement d’un intervalle à un autre | Alt + flèche gauche/droite |
| Déplacement d’un tier à un autre | Alt + flèche haut/bas |
| Supprimer la frontière de l’intervalle à gauche | Alt + retour arrière |
2.2 Modification structurelle du .TextGrid
Une modification doit être effectuée sur les TextGrids : le changement du nom des tiers des phonèmes (nommé MAU par WebMAUS) et des syllabes (MAS). Ils doivent être nommés phones et syl, respectivement. Ceci est dû au fonctionnement de ProsoProm, un des scripts qui sera utilisé pour les analyses.
La modification du nom des tiers peut se réaliser individuellement lors de la vérification manuelle de chaque TextGrid (Tier > Rename tier…) ou en batch à l’aide d’un logiciel d’édition de texte/de code tel que
Notepad++ ou
Sublime Text.
Sur Sublime Text, ce changement se fait avec la commande d’édition multiple Ctrl+Shift+F. Cette commande vous permet d’aller chercher la ligne de code qui contient le nom des tiers que vous voulez modifier sur chaque .TextGrid et de la remplacer par un autre nom.
Attention : Il est recommandé de faire un backup de vos fichiers avant de faire ce type de modifications !
Nous réaliserons trois changements :
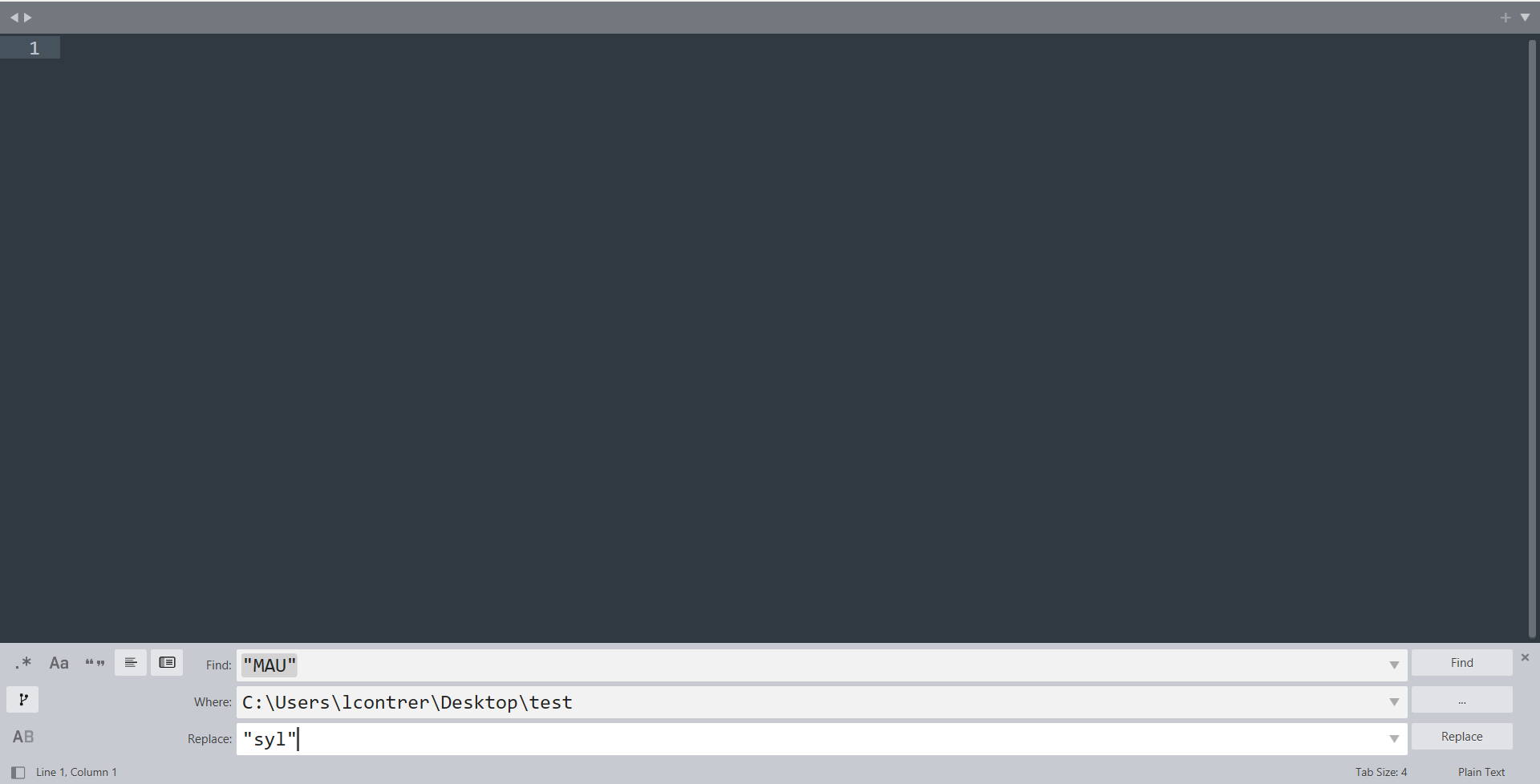
- Nous voulons chercher (champ Find) toutes les occurrences de
"MAU", avec les guillemets, et les remplacer (champ Replace) par"phones", guillemets inclus aussi. - Il en est de même avec
"MAS"➔"syll"pour le tier des syllabes . - Nous allons également coder tous les silences et les intervalles vides de la même façon, car Prosoprom l’exige:
- Il faut transformer les silences annotés comme
"<p:>"par WebMAUS en"_"(tiret du 8). - Il faut transformer tous les intervalles vides
""en"_"aussi.
- Il faut transformer les silences annotés comme
Dans toutes ces modifications, il ne faut surtout pas oublier les guillemets car ils font partie de la structure des intervalles dans le codage interne du TextGrid.
Sur le champ Where, il faut spécifier le chemin d’accès où se trouvent les TextGrids à modifier, comme illustré sur l’image :
Après cette manipulation, sauvegardez tous les fichiers qui ont été modifiés en cliquant sur File > Save All.
Étape 3 : Annotation des syllabes proéminentes
[Praat & ProsoBox]
Dans cette étape nous allons utiliser l’outil ProsoBox4, un plugin de Praat pour l’annotation et l’analyse prosodique. Le plugin contient des scripts à être exécutés de façon succéssive. Sa structure est la suivante :
Installez ProsoBox en exécutant le script setup.praat. Pour ouvrir un script, dans la fenêtre principale de Praat, cliquez sur Praat > Open Praat script…, puis cliquez sur Run > Run ou tapez Ctrl+R.
Cela installera un menu ProsoBox sur la fenêtre principale de Praat. Une fois ProsoBox installé, vous pourrez exécuter Prosogram, puis ProsoProm.
3.1 Prosogram
Cliquez sur Praat > ProsoBox3 > Prosogram v.24 (create nucl_table and plot graphics). Cela ouvrira une fenêtre de configuration avant de lancer les analyses.
- Sous la rubrique Input files, insérez le chemin d’accès du dossier où sont stockés les fichiers
.wavet.TextGrid, suivi de\*.wav, comme illustré sur l’image :
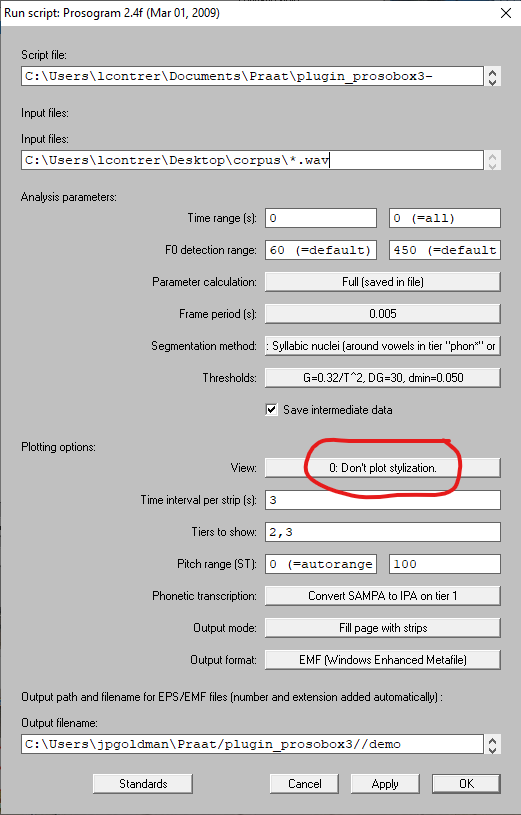
Sous la rubrique Analysis parameters vous pouvez laisser les propositions par défaut ou les modifier en fonction de vos besoins. Par exemple, si vous avez un locuteur ayant une voix très aiguë, modifiez la valeur maximale de détection de F0 à 500 Hz.
Sous la rubrique Plotting options, changez le paramètre View à
0: Don't plot stylization..
Cliquez sur le bouton OK et Prosogram commencera à réaliser des analyses prosodiques et à créer de nombreux fichiers nécessaires pour l’analyse de proéminence de ProsoProm.
3.2 ProsoProm
Cliquez sur Praat > ProsoBox3 > ProsoProm (creates syl_table from nucl_table). Une fenêtre de configuration similaire à celle de Prosogram s’ouvrira.
- Insérez le chemin d’accès de votre dossier en finissant par
\*.wav. - Cochez la case add relative parameters tiers.
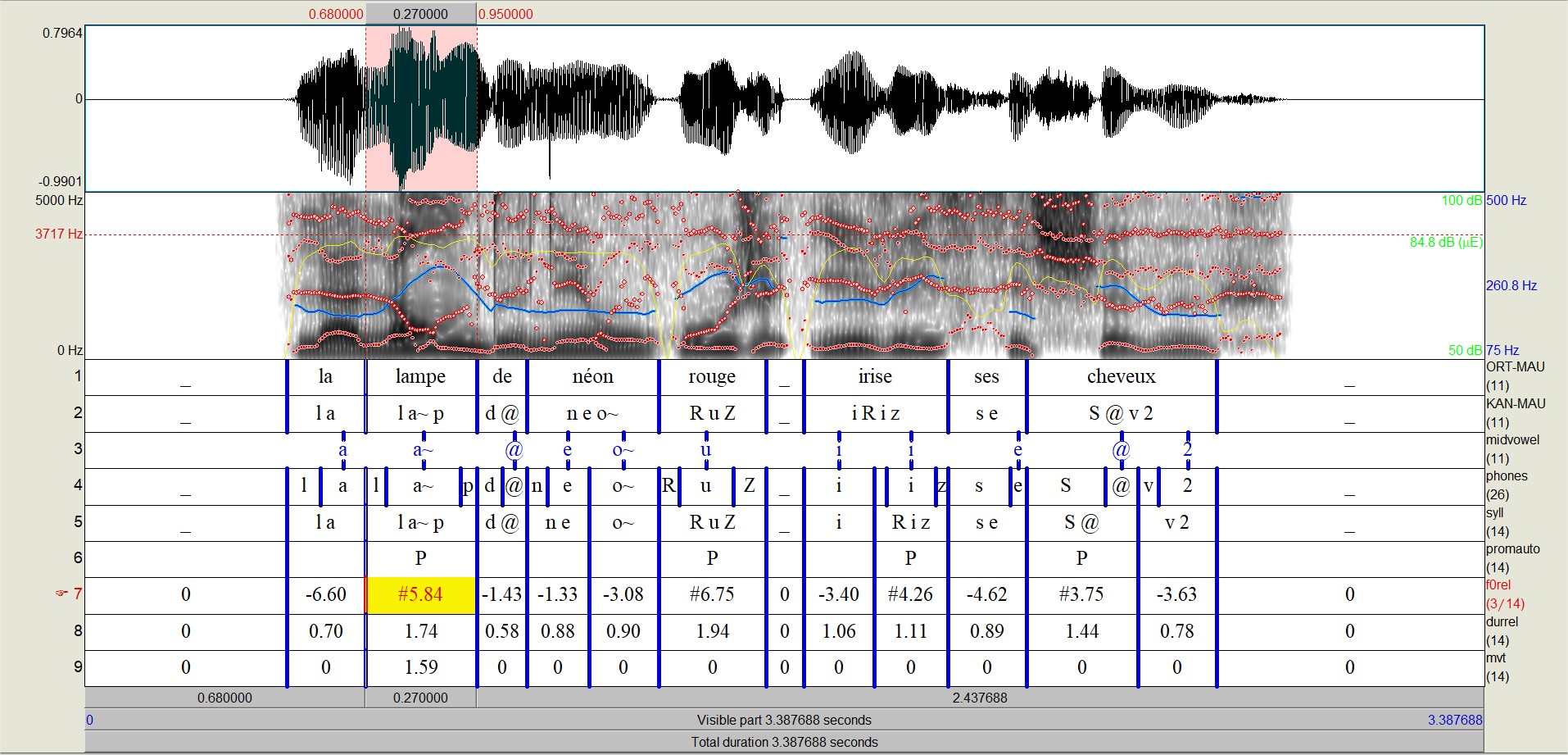
Cliquez sur le bouton OK et ProsoProm effectuera les analyses. Désormais, vos TextGrids auront cinq nouveaux tiers sur lesquels se trouvent les annotations relatives à la proéminence des syllabes :
Étape 4 : Extraction de données
[Praat]
L’extraction de données s’effectuera en deux temps :
- Une première extraction des indices prosodiques décrits dans Lowit et al.5
- L’extraction des annotations de proéminence effectuées par ProsoProm.
[à suivre]
Notes
Il existe des logiciels tels que Bulk Rename Utility pour Windows ou Smart File Renamer pour Linux
[sudo snap install smart-file-renamer]qui permettent de changer les noms de fichiers en masse (en batch). ↩︎Pour y accéder plus rapidement, il est possible de sauvegarder sous Favorite services les services les plus utilisés en cliquant sur l’étoile (surlignée en rose sur l’image). ↩︎
Dans cette étape, nous sélectionnons le format intermédiaire de traitement
.bpf, propre à WebMAUS. Il n’est pas utilisable directement sur Praat, mais nous le transformerons ultérieurement en.TextGrid. ↩︎Goldman, Jean-Philippe ; Simon, Anne-Catherine. ProsoBox, a Praat Plugin for Analysing Prosody. Speech Prosody (Tokyo, Japan, du 25/05/2020 au 28/05/2020). In: Proceedings Speech Prosody 2020, 2020. URL ↩︎
Lowit, Anja ; Marchetti, Agata ; Corson, Stephen ; Kuschmann, Anja (2018). Rhythmic performance in hypokinetic dysarthria: relationship between reading, spontaneous speech and diadochokinetic tasks. Journal of Communication Disorders, 72. pp. 26-39. URL ↩︎